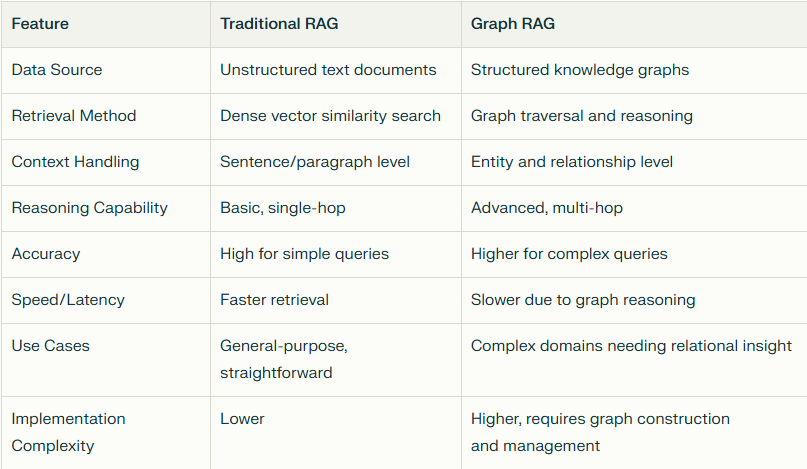
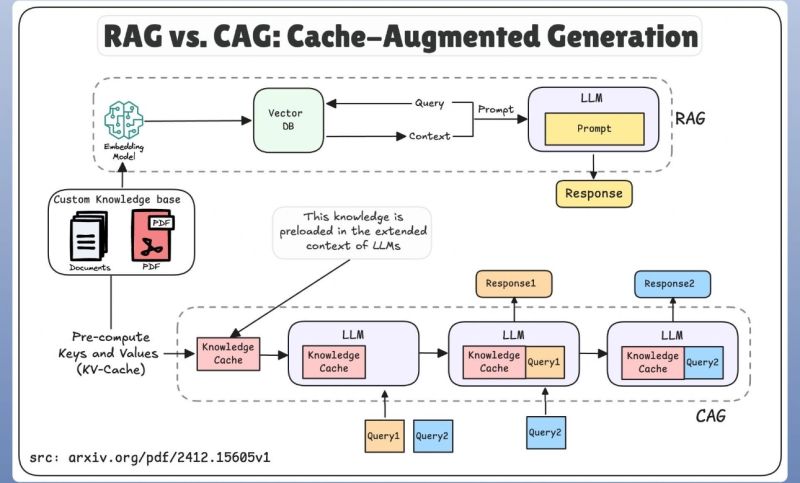
CAG is an improved RAG model that incorporates a caching layer to enhance performance and cost-effectiveness. It operates by storing frequently accessed or previously retrieved data, thereby “allowing faster retrieval without repeatedly querying the external knowledge base.” This design makes it “especially useful for high-traffic applications where speed and cost efficiency are essential.”
How CAG Works
CAG integrates a caching mechanism into the standard RAG workflow:
- User Query Submission: A user submits a query.
- Cache Lookup: The system first checks if the requested information is already present in the cache.
- Cache Hit: If the data is found in the cache, it is immediately retrieved, leading to “reducing query time and costs.”
- Cache Miss: If the data is not in the cache, the system proceeds to “fetch the relevant information from the external knowledge base.”
- Cache Update: The newly retrieved data is then “stored in the cache for future use,” enhancing efficiency for subsequent similar queries.
- Response Generation: The final response is delivered to the user, regardless of whether it originated from the cache or the external knowledge base.
Benefits of CAG
CAG offers several significant advantages, particularly for high-traffic, real-time applications:
- Faster Responses: Cached data “reduces retrieval time, enabling near-instant responses for common queries.”
- Cost Efficiency: By minimizing queries to external knowledge bases, CAG “lower[s] operational costs, making it a budget-friendly solution.”
- Scalability: It is “Ideal for high-traffic applications such as chatbots, where speed and efficiency are crucial.”
- Better User Experience: “Consistently fast responses improve user satisfaction in real-time applications.”
Limitations of CAG
Despite its benefits, CAG faces certain challenges:
- Cache Invalidation: “Keeping cached data updated can be difficult, leading to potential inaccuracies.”
- Storage Overhead: “Additional storage is needed to maintain the cache, increasing infrastructure costs.”
- Limited Dynamic Updates: CAG “may not always reflect the latest data changes in fast-changing environments.”
- Implementation Complexity: “Developing an effective caching strategy requires careful planning and expertise.”
Caching Options for Production Environments
For production-grade CAG implementations, dedicated caching services are highly recommended due to their scalability, persistence, and concurrency support.
- Python Dictionary (for testing/small scale):
- Pros: “Easy to implement and test,” “No external dependencies.”
- Cons: “Not scalable for large datasets,” “Cache resets when the application restarts,” “Cannot be shared across distributed systems,” “Not thread-safe for concurrent read/write operations.”
- Dedicated Caching Services (Recommended for Production):
- Redis:“A fast, in-memory key-value store with support for persistence and distributed caching.”
- Advantages: “Scalable and thread-safe,” supports “data expiration, eviction policies, and clustering,” works “well in distributed environments.” Provides “Persistence,” “Scalability,” and “Flexibility” with various data structures.
- Memcached:Description: “A high-performance, in-memory caching system.”
- Advantages: “Lightweight and easy to set up,” “Ideal for caching simple key-value pairs,” “Scalable for distributed systems.”
- Cloud-based Caching Solutions:
- AWS ElastiCache: Supports Redis and Memcached, “Scales automatically,” provides “monitoring, backups, and replication.”
- Azure Cache for Redis: Fully managed, “Supports clustering, geo-replication, and integrated diagnostics.”
- Google Cloud Memorystore: Offers managed Redis and Memcached, “Simplifies caching integration.”
Use Cases for CAG
CAG is highly effective in applications where speed and efficiency are paramount:
- Customer Support Chatbots: “Instantly answers FAQs by retrieving cached responses.” (e.g., e-commerce chatbot providing shipping/return policies).
- E-Commerce Platforms: “Retrieves product information, pricing, and availability instantly.” (e.g., immediate product details for a user search).
- Content Recommendation Systems: “Uses cached user preferences to provide personalized recommendations.” (e.g., streaming service suggesting movies based on watch history).
- Enterprise Knowledge Management: “Streamlines access to internal documents and resources.” (e.g., employees quickly retrieving company policies).
- Educational Platforms: “Provides quick answers to frequently asked student queries.” (e.g., online learning platforms delivering course details).
When CAG May Not Be Ideal
CAG is not universally suitable for all scenarios:
- Highly Dynamic Data Environments: “When data changes frequently, such as in stock market analysis or real-time news, cached information may become outdated, leading to inaccurate responses.”
- Low-Traffic Applications: “In systems with low query volumes, the overhead of caching may outweigh its benefits, making traditional RAG a better choice.”
- Confidential or Sensitive Data: “In industries like healthcare or finance, caching sensitive data could pose security risks. Proper encryption and access controls are necessary.”
- Complex, One-Time Queries: For “highly specific or unlikely to be repeated” queries, caching may offer minimal advantage and add “unnecessary complexity.”
CAG is expected to evolve by addressing its current limitations and enhancing its capabilities:
- Smarter Cache Management: Development of “Advanced techniques like intelligent cache invalidation and adaptive caching will help keep data accurate and up-to-date.”
- AI Integration: “Combining CAG with technologies like reinforcement learning could improve efficiency and scalability.”
- Wider Adoption: As AI systems advance, CAG “will play an important role in delivering faster, more cost-effective solutions across various industries.”
CAG represents a powerful enhancement to traditional Retrieval-Augmented Generation, offering significant improvements in latency and cost efficiency while maintaining accuracy. Despite its limitations, it stands out as “a powerful solution for high-traffic, real-time applications that demand speed and efficiency.” Its continued evolution is poised to “play a key role in advancing AI, improving user experiences, and driving innovation across industries.”convert_to_textConvert to source